II. RAPORT STIINTIFIC SI TEHNIC
PROIECT: Contributii la Misiunea Spatiala Euclid (CEM)
Etapa de executie nr. 2/13.11.2013
Raportarea rezultatelor obtinute in primul an de activitate al
proiectului
Titlu proiect: Contributii la Misiunea Spatiala
Euclid (CEM)
1.
Obiective
generale/specifice proiect:
2.1 Algoritmi si teste de dezvoltare pentru compresia datelor primare
obtinute de instrumentele VIS si NISP
2.2 Calibrare fotometrica bazata pe analiza de imagini
2.3 Optimizarea strategiei de masura din studiul efectului Sachs Wolfe Integrat
2.4 Diseminare si outreach
2.
Nr.
etapa / Denumire etapa:
Etapa 2: Raportarea rezultatelor obtinute
in primul an de activitate al proiectului
3.
Obiective
etapa:
4.1 Proiectarea
algoritmului de comprimare
4.2 Producerea
datelor de test
4.3 Definirea
cerintelor si strategiei pentru datele observationale la sol
4.4 Pregatirea
cataloagelor LSS
4.5 Demararea activitatilor de: implementarea
a algoritmilor de compresie, decompresie si autotest, testarea a algoritmilor
cu date simulate si reale si simulari numerice de CMB si LSS.
4.
Rezultate
planificate etapa
5.1 Documentatie continand
schita generala a software-ului pentru algoritmul de comprimare si justificarea
pentru selectia platformei hardware si a mediului de dezvoltare.
5.2 Documentatie continand
descrierea generarii de imagini si a procedurilor de adaptare ale acestora la
rezolutiile experimentului Euclid.
5.3 Colectie de imagini
astronomice pentru testarea algoritmului de compresie
5.4 Documentatie continand
descrierea datelor la sol ce vor fi folosite si a software-ului standard
acceptat de Consortiul Euclid.
5.5 Documentatie continand descrierea
metodologiei de constructie si a caracteristicilor catalogului de trasori
de materie.
5.6 Harti reprezentand
proiectii 2D ale campului de densitate,
in format compatibil cu HEALPIX.
Toate
rezultatele planificate pentru aceasta etapa au fost integral realizate. De
asemenea, au fost demarate fara intarzieri toate activitatile planificate in
aceasta etapa a proiectului.
6. RST – Raport Stiintific si Tehnic in extenso (maxim
20 de pagini pentru etapa intermediara)
6.1
Rezumatul etapei
In
aceasta etapa au fost incheiate activitatile din:
-
WP1.2: Proiectarea
algoritmului de comprimare
-
WP1.3: Producerea
datelor de test
-
WP2.1: Definirea
cerintelor si strategiei pentru datele observationale la sol
-
WP3.1: Pregatirea cataloagelor LSS
De
asemenea, au fost demarate sau s-au aflat in desfasurare activitatile din:
WP1.4 Implementarea algoritmilor de compresie,
decompresie si autotest, WP1.5 Testarea a algoritmilor cu date simulate si
reale si WP3.2 Simulari numerice de CMB
si LSS.
Astfel,
in aceasta etapa am realizat schema
generala a pachetelor software (compresie, decompresie si rutine de
auto-testare) precum si alegerea formatului in care vor fi stocate datele,
folosind ca input concluziile WP1.1. In plus, a fost aleasa platforma
hardware(PC cu posibilitate de portare ulterioara pe LEON3) si a mediul de
dezvoltare(C++ pentru Windows cu posibilitatea de adaptare la RTEMS) ce vor fi
folosite pentru realizarea pachetelor software; alegerea a fost facuta in asa
fel incat sa fie in acord cu alti membri ai Consortiului Euclid ce desfasoara activitati
similare.
Pentru
testarea software-ului de compresie am realizat o colectie de imagini
astronomice. Imaginile au fost adaptate din imagini reale, luate din cataloage
publice si prelucrate cu ajutorul programului Aladin pentru a fi in
conformitate cu caracteristicile instrumentale ale Misiunii Euclid.
Am
finalizat identificarea misiunilor observationale la sol pentru segmentul
stiintific la sol al Misiunii Euclid(Euclid ground science segment) si a
pachetelor software ce urmeaza a fi folosite. Si aceste activitati au fost
realizate in deplina concordanta cu activitatile Consortiul Euclid.
De
asemenea, am realizat un catalog de galaxii utilizand cataloagele publice ale
misiunilor observationale curente, si am construit harti reprezentand proiectii
de densitate, in format HEALPix.
Schita
pachetului software, colectia de date astronomice, softurile de manipulare a imaginilor
si cataloagele de galaxii reprezinta livrabile interne ce urmeaza a fi folosite
de urmatoarele WP.
6.2
Descrierea stiintifica si tehnica, cu punerea in evidenta a rezultatelor etapei
si a gradului de realizare a obiectivelor – se vor indica rezultatele si modul
de diseminare a rezultatelor
6.2.1
Proiectarea algoritmului de comprimare.
Datele
stiintifice obtinute de la senzorii experimentului Euclid se prezinta sub forma
unui sir de date binare, cu rezolutia de 16 biti.
Rolul
algoritmului de comprimare este de a efectua o compresie a volumului de date de
intrare, dupa o metoda care sa permita ca la decomprimare sa se refaca datele
initiale, fara nici o pierdere de informatie. Un astfel de algoritm se numeste
algoritm de tip „lossless”, adica algoritm fara pierdere de informatie.
Algoritmul „lossless” ales este algoritmul de comprimare Rice, care se preteaza
foarte bine la datele obtinute de la senzorii experimentului Euclid. Acest
algoritm a fost folosit cu succes pe mai multe misiuni cosmice si si-a dovedit
efeicienta in ceea ce priveste performantele de comprimare.
Algoritmul
ce va fi proiectat este compus in principal din doua blocuri software succesive
(Figura 1).

Fig. 1. Schema bloc a algoritmului de compresie Rice.
Primul
bloc este blocul pre-procesor, urmat de blocul codor adaptiv dupa entropie. Secventa
de date de la intrarea codorului de compresie este formata din esantioane de
date xi. Acesta secventa de date este impartita in sub-blocuri a
cate J esantioane fiecare. Deci sub-blocul de date de intrare poate fi notat cu
xi = x1, x2, .... xJ. Valoarea
numarului J este aleasa 8, 16 sau 32. Uzual a fost aleasa ca valoare optima
valoarea 16. Rolul acestei preprocesari este de a face o decorelare a datelor
de intrare in vederea imbunatatirii procesului de compresie in codorul adaptiv.
La iesirea blocului preprocesor rezulta un sir de 16 esantioane de date,
decorelate, δi = δ1 , δ2 , ...
δJ. Acest sir de 16 valori se aplica la intrarea celui de al
doilea bloc, denumit „Codor de entropie adaptiv - CEA”. In cadrul acestui codor
de entropie adaptiv se opereaza asupra setului de 16 valori δi cu o serie de algoritmi de comprimare,
verificand care dintre valorile comprimate au dimensiunea cea mai scurta ca
numar de biti. Valoarea cea mai scurta este determinata de entropia setului de
date de la intrare si de optiunea utilizata pentru compresie. Valoarea cea mai
scurta identificata, precedata de un set de biti de identificare (ID-optiune)
este adaugata la sirul de date codate (Coded Data Set = CDS) rezultat la
iesire. Succesiunea de seturi de date codate CDS formeaza datele de iesire
comprimate y (Figura 1).
Diagrama
logica pentru programul general de compresie este data in Figura 2.
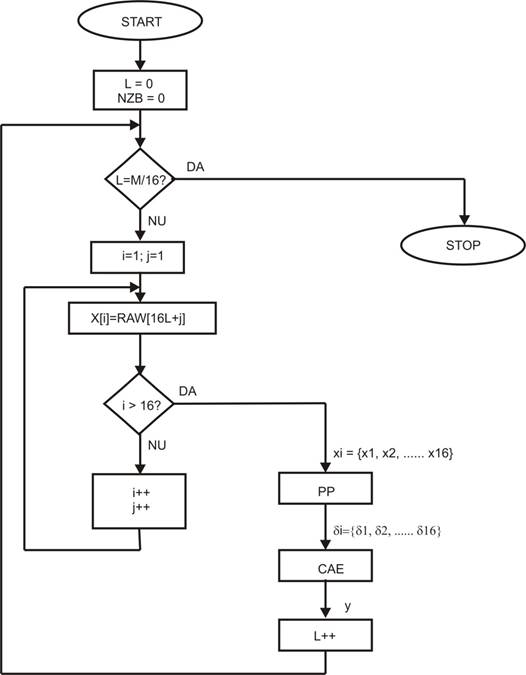
Fig. 2. Diagrama logica pentru programul general de compresie.
Blocul
de date de la intrare este obtinut de la senzorul instrumentului, care are un
numar de M pixeli de imagine: RAW(x) = [x1, x2, x3, ......xM]. Daca numarul
pixelilor nu este un multiplu de 16, se completeaza la sfarsit datele cu valori
zero pana se ajunge la un multiplu: M = 16 * L. La pornirea programului, acesta
va initializa valoarea lui L = 0, astfel incat vor fi citite primele 16 valori
RAW(x) = [x1, x2, .....x16]. Aceste 16 valori vor fi folosite ca prim sub-bloc
ce va fi prelucrat de subrutina pre-procesor (PP) care va furniza 16 valori
preprocesate [δ1, δ2, ...δ16]. Acestea vor intra ca date de
intrare a subrutinei codorului adaptiv de entropie (CAE). Aici datele vor fi
comprimate si rezultatul va fi alipit la sirul de date codate y de la iesire. Odata ciclul terminat,
se incrementeaza valoarea lui L (L = 1) si se vor citi urmatoarele 16 valori
din datele de intrare initiale: RAW (x) = [x17, x18, .... x32], care vor fi
transferate ca 16 valori xi la intrarea preprocesorului. Si astfel
ciclul se repeta pana la epuizarea ultimei data de intrare xM = x16L.
In acel moment programul se opreste, iar in blocul de date y vom avea datele
comprimate prin metoda algoritmului Rice.
In
cazul instrumentului VIS de pe misiunea Euclid, imaginile intunecate ale
cerului de fond alterneaza cu imagini de intensitate diferita ale stelelor. Din
aceasta cauza, avand in majoritate valori ale semnalului aproape de zero,
pentru pre-procesor se preteaza un algoritm cu „Unit delay predictor”. In
esenta, principiul pre-procesorului cu „predictor” consta in estimarea in avans a fiecarei
valori de esantion ce intra in pre-procesor, iar in primul modul al
pre-procesorului se face diferenta intre valoarea reala xi a
esantionului de la intrare si valoarea estimata a acestuia. Schema bloc a preprocesorului poate fi vazuta
in Figura 3.
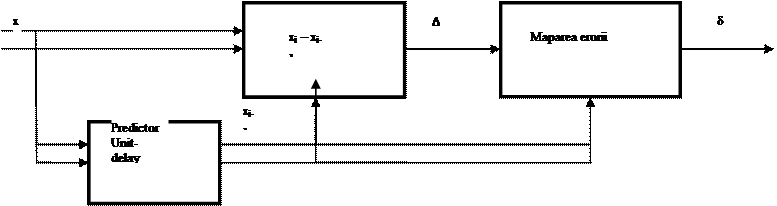
Fig. 3. Schema bloc a pre-procesorului.
In
cazul „unit delay predictor” valoarea estimata este egala cu valoarea
esantionului anterior, xi-1.
Se
obtine eroarea de estimare Δi = xi – xi-1,
care se transmite mai departe. Aceasta valoare insa poate fi atat pozitiva, cat
si negativa. Din aceasta cauza, semnalul Δi intra in modulul de
„mapare a erorii”, pentru a fi convertit in valori pozitive δi,
ce vor fi transmise la iesirea pre-procesorului. Avand in vedere ca semnalul
nostru trebuie sa aiba doar valori pozitive, cu o rezolutie de 16 biti,
rezulta, conform standardului CCSDS 121.0-B-2, ca maparea erorii poate fi
facuta dupa urmatarea formula:
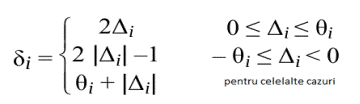
unde θ
i = minimul (xi-1 , 216 -1 – xi-1 )
Diagrama
logica a algoritmului proiectat pentru unitatea pre-procesorului este data
in Figura 4.
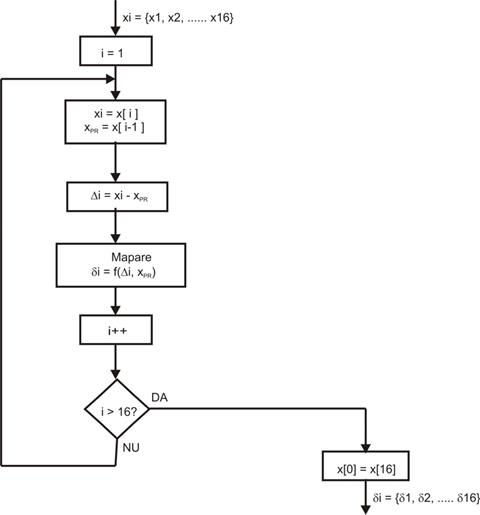
Fig. 4. Diagrama logica pentru unitatea pre-procesor.
La
intrare programul primeste un set de 16 valori xi de date initiale,
brute. La iesirea blocului software se obtine un set de 16 valori preprocesate
δi , convenabile pentru un mai mare grad de compresie in urmatorul bloc software,
cel de codare adaptiva dupa entropie.
Schema
bloc a codorului adaptiv dupa entropie este data in Figura 5.
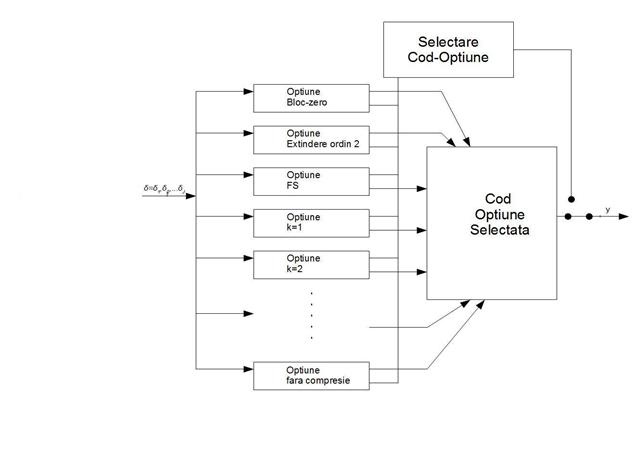
Fig. 5. Schema bloc a codorului adaptiv dupa entropie.
La intrarea codorului se aplica
un sub-bloc de date format din cele 16 valori δi rezultate la
iesirea pre-procesorului. Asupra acestui sub-bloc se aplica o serie de metode
de compresie, dupa algoritmi specifici fiecarei optiuni: optiune bloc-zero,
optiune extensie de ordinul 2, optiune „fundamental sequnce” (FS), optiune k =
1, obtiune k=2, .... optiune k=13, , optiune fara compresie. La iesirea
fiecarui bloc-optiune de compresie se obtine cate o secventa de biti, cu
lungimi diferite, functie de eficienta de compresie a fiecarei optiuni. In fata
fiecarei secvente rezultate se ataseaza codul de identificare binar (ID),
specific fiecarei optiuni, obtinandu-se cate un set de date codate (CDS) pentru
fiecare optiune. In majoritatea cazurilor cuvintele codate sunt de lungime mai
mica decat sub-blocul de la intrare δi.
Din standardul CCSDS 121.0-B-2 am
extras codurile de identificare ID pentru optiunile de compresie, folosite in
cazul nostru cu rezolutia de 16 biti a esantioanelor procesate. Ele sunt date
in Tabelul 1.
Tabelul
1. Codurile de identificare ID pentru optiunile codorului dupa entropie.
|
Optiunea de codare |
Nume ID |
Valoare ID (binar) |
|
Bloc-zero |
ID_BZ |
00000 |
|
Extindere de ordin 2 |
ID_E2 |
00001 |
|
FS |
ID_FS |
0001 |
|
k = 1 |
ID_k1 |
0010 |
|
k = 2 |
ID_k2 |
0011 |
|
k = 3 |
ID_k3 |
0100 |
|
k =4 |
ID_k4 |
0101 |
|
k = 5 |
ID_k5 |
0110 |
|
k =6 |
ID_k6 |
0111 |
|
k =7 |
ID_k7 |
1000 |
|
k = 8 |
ID_k8 |
1001 |
|
k = 9 |
ID_k9 |
1010 |
|
k = 10 |
ID_k10 |
1011 |
|
k = 11 |
ID_k11 |
1100 |
|
k = 12 |
ID_k12 |
1101 |
|
k =13 |
ID_k13 |
1110 |
|
Fara compresie (No Compression) |
ID_NC |
1111 |
Functia “selectare cod-optiune”
va selecta care din seturile de date codate CDS are lungimea cea mai scurta si
aceasta este aleasa pentru a fi transmisa la iesirea codorului si atasata la
sfarsitul datelor de iesire compresate y
.
Programul
care sa indeplineasca aceste functii descrise mai sus are diagrama logica de functionare data in Figura 6.
Urmarind diagrama logica, deducem functionarea programului. La intrarea
modulului „Codor adaptiv dupa entropie” (CAE) sunt introduse 16 valori de date
δi . Se verifica in prima secventa daca suma tuturor valorilor
δi este egala cu zero, adica daca sub-blocul de date este un
„Zero-Block”. Daca da, variabila NZB (Numar de Zero-Block) este incrementata cu
o unitate. Mentionam ca la pornirea programului NZB este initializat la zero (Figura
2). Programul trece direct la iesirea CAE, variabila L se incrementeaza (Figura
2) si se citeste urmatorul sub-bloc de 16 valori. Daca este tot un Zero-Block,
se mareste NZB la 2 si asa mai departe pana cand se intalneste un sub-bloc diferit
de zero. In acel moment programul urmareste ramura verticala a diagramei logice
(Figura 6) si se testeaza cate sub-blocuri egale cu zero au fost. Daca numarul
e cel putin 1, se urmareste decizia DA si se trece pe ramura din dreapta, unde
se intra in modulul „Codare Zero-Block”. Aici, se obtine cuvantul codat
corespunzator, cu ID_ZB in fata. Se initializeaza valoarea NZB la zero, se
revine la sub-blocul diferit de zero refacand valoarea corespunzatoare pentru
L (L= L-1). Apoi cuvantul codat anterior
(CDS_ZB) se alipeste la sfarsitul secventei y. Dupa care se reciteste sub-blocul L-1 diferit de zero, care
trece in diagrama logica pe ramura NU
(NZB>0?). Acest sub-bloc este comprimat dupa diverse optiuni intr-o serie de
module succesive:
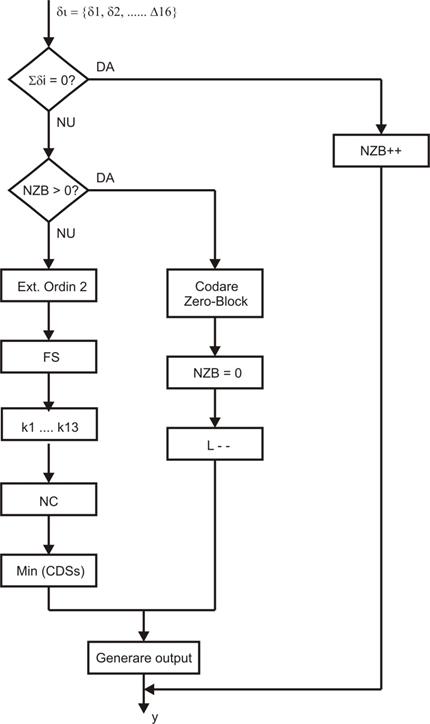
Fig. 6. Diagrama logica pentru blocul codorului adaptiv dupa entropie.
„Extensie
de ordinul 2” (Ext. Ordin 2), „Fundamental sequence” (FS), „Splitare de ordin k
a esantionului” (k1, k2, k3, ....k13), si optiunea „Fara compresie (NC – No
compression). Fiecare modul software furnizeaza cate un CDS de diverse lungimi,
avand in fata codul de identificate respectiv: ID_E2, ID_FS, ID_k1, ID_k2, ...
ID_k13 sau ID_NC. Ultimul modul de pe aceasta ramura a programului - Min(CDSs)
identifica setul de date codate CDS cu lungimea cea mai scurta (minima), pe
care o trimite mai departe la modulul „Generare output”, unde CDS-ul ales este
adaugat la sfarsitul secventei y. Dupa care se incrementeaza din nou valoarea
lui L (L = L+1, Figura 2) pentru citirea si procesarea urmatorului sub-bloc de
date.
Modulul
“Extensie de ordin 2” realizeaza comprimarea sub-blocului de date in felul
urmator: cele 16 valori δi de la intrarea codorului adaptiv de
entropie sunt grupate doua cate doua si procesate dupa un anume algoritm. Se
obtin 8 valori ti, care vor fi apoi codate dupa metoda FS –
Fundamental Sequence. Formula de procesare a perechilor de valori de intrare
este:
t
= (δi + δi+1) (δi + δi+1
+1)/2 + δi+1
Eficienta
optiunii de comprimare consta in faptul ca setul de date codate CDS (Coded Data
Set) este format doar din 8 cuvinte codate FS, in loc de 16. In al doilea rand,
optiunea este eficienta cand valorile initiale de intrare xi au
valori foarte mici, sub 2 biti pe esantion.
Diagrama
logica pentru programul modulului „Ext. Ordin 2” este data in Figura 7.
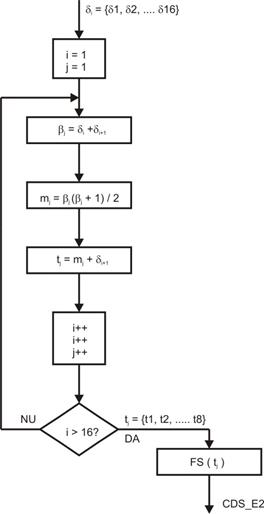
Fig. 7. Diagrama logica de functionare a modulului optiune „Ext. Ordin 2”.
La
intrarea modulului “Extensie de ordin 2”
se introduce secventa de 16 esantioane δi. Se
initializeaza indicii i si j la valoarea 1. Se aduna primele doua valori de
intrare si se obtine o noua valoare, β1 = δ1 +
δ2. Urmatoarea functie software va obtine valoarea m1
= β1 (β1 + 1) / 2.
O noua functie va procesa
valoarea t1 = m1 + δ2. Dupa obtinerea
primei din cele 8 valori de iesire, indicele i se incrementeaza de doua ori,
iar indicele j o singura data. In acest fel se vor citi urmatoarele 2 valori de
la intrare δ3 si δ4
si se va obtine dupa procesare a doua valoare t2. Cand au fost
citite toate cele 16 valori ale sub-blocului de intrare, cele 8 valori tj
vor fi codate dupa metoda FS si vor fi alipite in urma codului de identificare
ID_E2. Se va obtine la iesirea modulului „Ext. Ordin 2” setul de date codate
CDS_E2.
Modulul „Fundamental sequence -
FS” codeaza un esantion dupa urmatoarea logica: valoarea codata, exprimata in
binar, este formata dintr-un numar de „0” succesivi egal cu valoarea zecimala a
esantionului, urmati de o valoare „1” la final. In tabelul 2 putem vedea acest
mod de codare.
Tabelul
2. Codarea tip FS.
|
Valoarea zecimala a δi
|
Codul FS (binar) |
|
|
|
|
0 |
1 |
|
1 |
01 |
|
2 |
001 |
|
3 |
0001 |
|
... |
... |
|
... |
... |
|
... |
... |
|
216 – 1 |
000...00001 [(216 –
1) de zerouri] |
Daca probabilitatea de aparitie a
valorilor mai mici decat 15 pentru
esantioane este mult mai mare decat pentru valorile mari, setul de date codat
CDS prin metoda FS va avea o lungime mai mica decat sub-blocul initial δi
. Diagrama logica a programului ce va implementa acest tip de codare este data
in Figura 8.
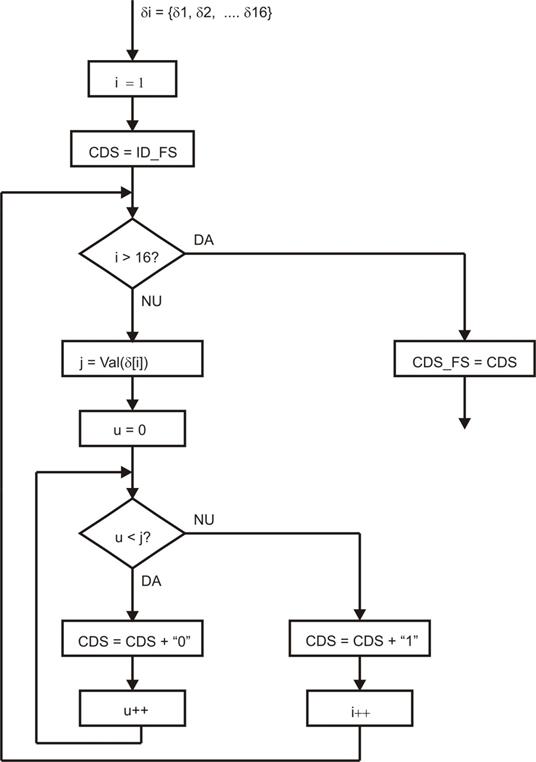
Fig. 8. Diagrama logica pentru modulul „Fundamental sequence”.
La
intrarea modulului FS se introduce secventa de 16 esantioane δi.
La iesirea submodulului se va obtine setul de date codate (Coded Data Set:
CDS_FS) pentru sub-blocul de 16 valori de la intrare. Mentionam ca CDS va fi un
numar binar, adica va fi constituit dintr-o succesiune de biti cu valoare „0”
sau „1”. Programul initializeaza valoarea lui i la valoarea 1, pentru citirea
primei valori δ[1]. Valoarea CDS se initializeaza cu ID_FS, corespunzator
acestei optiuni de codare. Variabila „j” se initializeaza cu valoarea zecimala
a lui δ[1]. Apoi programul intra intr-o bucla de j iteratii, care adauga
la CDS un numar j de zerouri, iar la sfarsit adauga un bit cu valoarea „1”.
Apoi valoarea lui i se incrementeaza
cu unu pentru a citi al doilea esantion pe care il codeaza si il alipeste la
CDS. Dupa alipirea tuturor cuvintelor codate pentru cele 16 esantioane din
sub-bloc, la iesire se obtine setul de date codate CDS_FS, dupa optiunea
FS-Fundamental sequence.
Submodulele de codare dupa
optiunile k=1; k=2; k=3; ....k=13, presupun o splitare a fiecarui esantion de
intrare δ[i] exprimat binar, in doua parti. Ultimii k biti, cei mai putin
semnificativi, de la fiecare esantion sunt separati si alipiti (concatenati)
intr-o secventa de biti necomprimata, notata cu „k_SPLIT”. Aceasta secventa se
va alipi la sfarsitul setului de date codate CDS_k. Valorile esantioanelor cu
rezolutie de (16-k) biti ramase dupa splitare vor fi codate dupa metoda
„Fundamental sequence – FS”. Setul de date codate CDS_k va fi format din
concatenarea a trei parti: codul de identificare ID_k, datele de rezolutie
(16-k) biti codate dupa modelul FS si secventa de biti necomprimata (necodata),
notata cu „k_SPLIT”.
Diagrama
logica pentru aceste optiuni de comprimare este data in Figura 9.
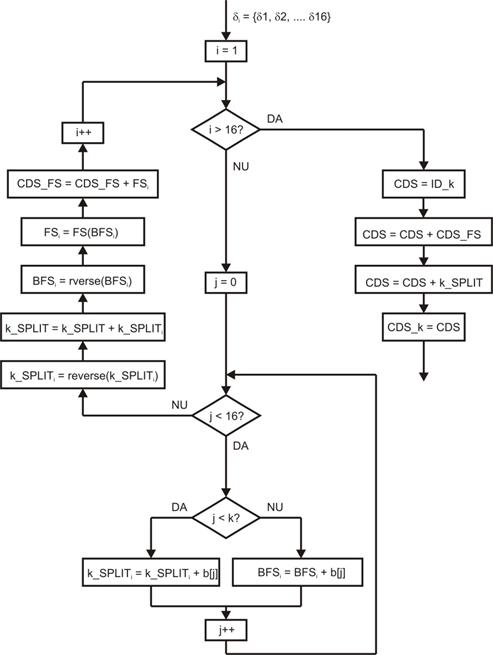
Fig. 9. Diagrama logica pentru modulele-optiune de ordin k ( k = 1, 2,
...13).
Variabila
i se initializeaza la valoarea 1 si
se incrementeaza pentru a citi succesiv cele 16 esantioane de date de la
intrare. Variabila j se
initializeaza la valoarea zero si se incrementeaza pentru a citi succesiv cei
16 biti ai fiecarei valori binare cu rezolutia de 16 biti. Partea de jos a
diagramei se realizeaza printr-o instructiune imbricata „for-if-else” care va
splita esantioanele binare in k biti necomprimati (k_SPLITi ) si
(16-k) biti BFSi. Dupa operatiunea de splitare, cele doua parti
obtinute au bitii asezati in ordine inversa (bitul de ordin zero in pozitia
celui mai semnificativ bit). Din aceasta cauza, cele doua parti splitate
trebuie sa inverseze ordinea bitilor
printr-o instructiune „reverse”. Apoi esantionul BFSi va fi
comprimat dupa metoda „Fundamental sequence” rezultand FSi. Cele 2
secvente sunt concatenate separat pentru cele 16 esantioane (partea stanga a
diagramei) si rezulta pentru intreg sub-blocul de la intrare doua siruri de biti:
k_SPLIT si CDS_FS. Ramura verticala din dreapta diagramei arata cum se obtine
la iesire setul de date codate CDS_k: se insumeaza (alipeste) in ordine: codul
de identificare ID_k, secventa codata CDS_FS si setul de biti splitati k_SPLIT.
Submodulul cu optiunea „Fara
codare” (No Coding – NC) are diagrama de functionare logica data in Figura 10.
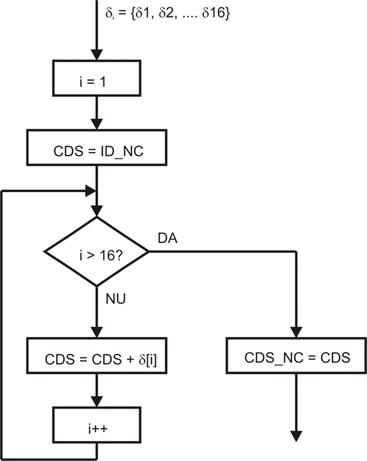
Fig. 10. Diagrama logica pentru optiunea „Fara codare”.
La inceput se
initializeaza variabila i la valoarea 1 pentru a citi prima data de
intrare δ[1]. CDS se initializeaza cu valoarea ID_NC, corespunzatoare
optiunii fara codare. Se citeste prima valoare din blocul de la intrare si se
alipeste la CDS, fara nici o compresie. Apoi se incrementeaza succesiv valoarea
lui i pentru a citi fiecare din cele 16 date de intrare si a le alipi
fara compresie la CDS. La iesire se obtine setul de date CDS_NC.
Optiunea „Block-Zero” se
utilizeaza cand unul sau mai multe sub-blocuri de date preprocesate i
contin numai valori egale cu zero. Se poate intampla acest lucru in procesul de
calibrare, cand toate valorile obtinute de la senzor sunt egale. In cazul in
care numarul de esantioane de comprimat este foarte mare, cum este si in cazul
nostru, sirul de esantioane de intrare se segmenteaza in intervale de
referinta, fiecare avand un numar maxim r
de 4096 sub-blocuri de date a cate J
date fiecare sub-bloc (CCSDS 121.0-B-2). In cazul nostru, cu J=16, numarul
maxim de esantioane dintr-un interval de referinta este r=65.536 valori.
Fiecare interval r se subdivide in
segmente de cate 64 valori (s=64).
Acest lucru va permite codarea in cazul optiunii „Zero-Block”. Daca avem o succesiune de n sub-blocuri continand toate valorile egale cu zero, codarea se va
face in mod asemanator optiunii „Secventa Fundamentala – FS”, dupa modelul din
tabelul 3.
Tabel
3. Cuvintele codate pentru optiunea „Bloc-Zero”.
|
Numarul n de sub-blocuri „Bloc-Zero” |
Cuvant codat FS |
|
|
|
|
1 |
1 |
|
2 |
01 |
|
3 |
001 |
|
4 |
0001 |
|
ROS |
00001 |
|
5 |
000001 |
|
6 |
0000001 |
|
... |
... |
|
... |
... |
|
... |
... |
|
63 |
000...00001 [63 de zerouri si un
„1”] |
Diagrama
logica pentru programul modulului „Bloc-Zero” va fi deci asemanatoare cu
diagrama din Figura 8, pentru modulul „Fundamental sequence”. ROS (Remainer of
segment) se utilizeaza in cazul in care avem 64 de sub-blocuri consecutive
egale cu zero.
Structura pachetului de date codate.
Fiecarui
sub-bloc de 16 valori de date RAW de la intrare ii corespunde cate un set de
date codate CDS. Pachetul de date codate de la iesire va fi format deci dintr-o
succesiune de seturi CDS (Figura 11). Intrucat avem un preprocesor de tip „Unit
delay predictor”, este necesar ca la fiecare al r = 4096-lea sub-bloc de date
codat sa avem un set de date codate CDS de tip „cu esantion de referinta” (Figura
12). Acest CDS va fi compus din ID-ul optiunii de codare, urmat de prima
valoare din sub-blocul de intrare (ca referinta), iar apoi datele comprimate de
la cele 15 valori ramase din sub-bloc. Deci, toate seturile de date codate
CDS-1, CDS-(r+1), CDS-(2r+1), .... vor avea structura data in figura 12. Toate
celelalte seturi de date codate CDS vor fi compuse doar din ID-ul optiunii de
comprimare urmat de setul de date comprimate de la 16 valori succesive de
intrare (Figura 13).
![]()
Fig. 11. Structura pachetului de date codate y.

Fig. 12. Structura unui set de date codate cu esantion de referinta.

Fig. 13. Structura unui set de date codate fara esantion de referinta.
Pentru
cazul nostru in care numarul esantioanelor de intrare este mai mare decat 4096
x 16 = 65.536, va trebui sa realizam acest tip de inserare a valorii referintei
la fiecare interval r = 4096. In
acest caz, diagrama logica din figura 2 va trebui sa fie modificata ca in
figura 14. Valoarea lui r se
initializeaza la inceputul programului la valoarea 1 si se reinitializeaza la
aceiasi valoare dupa 4096 de sub-blocuri procesate.
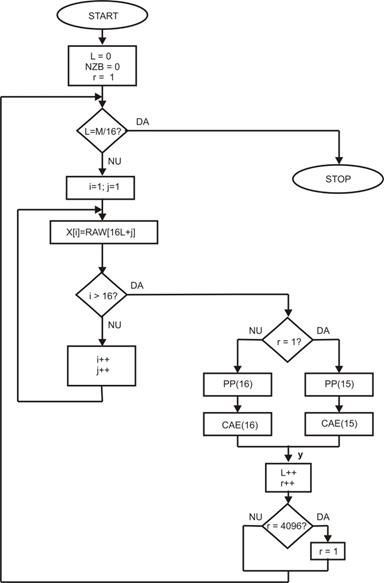
Fig. 14. Diagrama logica de codare cu valori de referinta (r = 4096)
Dupa citirea celor 16 esantioane
din sub-bloc, se testeaza valoarea lui „r”. Daca aceasta este egala cu 1, adica
suntem la inceputul unui interval de referinta, blocurile software PP(15) si
CAE(15), vor comprima numai ultimele 15 valori din sub-bloc, pe care le vor
alipi dupa ID-optiune si valoarea de referinta, formata din prima valoare
nemodificata. Pentru toate celelalte valori ale lui r, blocurile software PP(16) si CAE(16) vor comprima toate cele 16
valori si va rezulta un CDS ca cel din Figura 13.
Diagramele logice proiectate mai
sus vor fi implementate (codate) in limbajul de programare C/C++ pentru fiecare
modul software in parte. Aceste programe sunt portabile astfel ca vor putea fi
instalate si pe o placa de dezvoltare GR712RC, dotata cu un procesor SPARC de
tip LEON3.
Pentru a verifica daca procesul
de codare a decurs corect, este necesar ca datele codate sa fie decodate si
comparate cu setul de date RAW initiale.
O schema-bloc a decodorului este data in Figura 15.

Fig. 15. Schema-bloc a decodorului.
In procesul de decodare,
algoritmul trebuie sa efectueze operatiunile inverse codarii. La intrarea
decodorului se introduce setul de date comprimate y. Intr-un prim bloc denumit „Decodor Adaptiv dupa Entropie” se
realizeaza operatia inversa operatiei de compresie si se obtin datele δi,
precum si valoarea de referinta din primul CDS al fiecarui interval de
referinta cu dimensiunea r. Aceste
valori sunt introduse in blocul „Post-Procesor”, care reface sirul de date
necomprimate xi.
Diagrama
de functionare logica a decodorului poate fi vazuta in Figura 16.
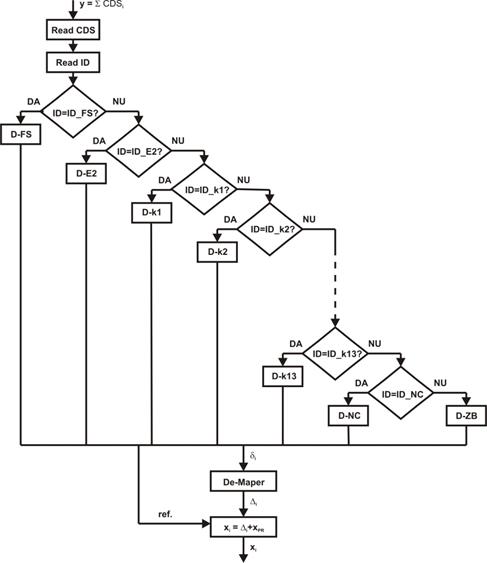
Fig. 16. Diagrama logica de functionare a decodorului.
La intrarea decodorului se
introduce blocul de date codat y,
format dintr-o succesiune de seturi de date codate (CDSi). Programul
citeste pe rand fiecare set de date codate CDS. De la inceputul lui CDS se
extrage valoarea ID. Cu ajutorul unei instructiuni de tip „if-else-if” se
identifica tipul de ID, care poate fi: ID_FS, ID_E2, ID_k1, ID_k2, .....
ID_k13, ID_NC sau ID_ZB. In functie de tipul de ID identificat, setul de date
codate din CDS este indreptat spre modulul decodor corespunzator: D-FS, D-E2,
D-k1, D-k2, ...... D-k13, D-NC sau D-ZB. La iesirea decodorului ales se obtin
cele 16 valori δi. Din primul CDS al fiecarui set de referinta r se obtine si valoarea de referinta
necesara pentru blocul „Post-Procesor”. Valorile δ i intra in
primul modul al blocului „Post-procesor”, si anume in modulul „De-Maper”. La
iesirea acestuia se obtin valorile ∆i dupa o functie inversa
celei din modulul „Maper” de la comprimare. Urmeaza un modul care reface
valorile initiale xi dupa formula: xi = ∆i
+ xPR, unde xPR
este valoarea predictorului. De retinut ca valoarea initiala a lui xPR
este egala cu valoarea de referinta (xPR [1] = ref.). Setul de 16
valori xi obtinute la iesire se alipeste la sirul de date necodate x rezultat la iesire.
6.2.2 Producerea datelor de test
In cadrul acestei activitati am produs o colectie
de imagini astronomice pentru testarea programului de compresie. Astfel,
imagini reale au fost stocate si adaptate pentru a respecta caracteristicile
instrumentale ale Misiunii Euclid.
Pentru realizarea acestei colectii, intr-o prima
etapa am folosit si adaptat programul public Aladin. Aladin este o unealta
software interactiva ce functioneaza ca un atlas interactiv al cerului, ce permite
utilizatorului sa vizualizeze imagini astronomice digitalizate si inputuri
suprapuse din cataloage si baze de date. Majoritatea imaginilor si cataloagelor
disponibile online sunt disponibile pentru vizualizare, analizare si prelucrare
in baza de date Aladin (SIMBAD, NED, VizieR, MAST/STScI, CADC, HEASARC, SLOAN,
NVSS).
Pentru prelucrarea imaginilor astronomice reale si
transformarea lor in imagini specifice Misiunii Euclid, am folosit optiunea FoV
(Field of View) a programului Aladin, care permite suprapunerea peste imagine a
campurilor vizuale ale diferitelor instrumente (existente sau definite de
utilizatori). Pentru a obtine imagini “simulate” in conditiile Misiunii, am
definit un camp vizual caracteristic pentru Euclid si l-am suprapus peste
imagini astronomice reale.
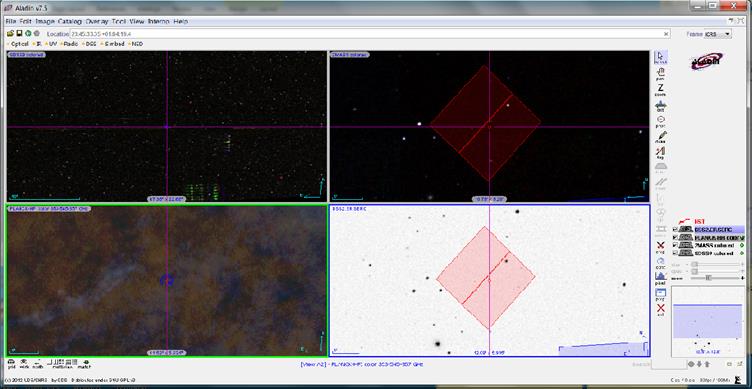
Figura 17.
Instantaneu obtinut din programul Aladin, reprezentand o regiune a cerului
scanata in diferite lungimi de unda: optic - SDSS Data Release 9 (panou stanga
sus) si DSS2 (panou dreapta jos), Radio- MisiuneaPlanck (panou stanga jos),
Infrarosu – 2MASS peste care a fost suprapus campul de vizualizare al Hubble
Space Telescope
In functie de rezultatele testelor programului de
compresie, vom decide daca este necesara cresterea precizicei (a numarului de
parametrii) cu care sa fie transformate imaginile astronomice in imagini ce
simuleaza outputul Misiunii Euclid.
6.2.3 Definirea
cerintelor si strategiei pentru datele observationale obtinute de experimentele
la sol
In aceasta etapa am finalizat activitatea prevazuta
in WP2.1, legata de identificarea misiunilor observationale la sol utile pentru
Misiunea Euclid si a softurilor ce urmeaza sa fie folosite. Aceste activitati
au fost facute in deplina concordanta cu Consortiul Euclid.
Datele broad-band obtinute de Euclid nu sunt
suficiente pentru a obtine redshift-uri fotometrice suficient de precise,
astfel ca sunt necesare date aditionale, provenite de la experimentele la sol.
Aria de observare a experimentului Euclid (ce acopera 15,000 grade2)
trebuie sa fie observata si cartografiata de experimentele la sol
folosind cel putin 4 filtre care sa acopere cel putin intervalul de lungimi de
unda 429-930 nm; suprapunerea dintre filtre trebuie sa fie de cel putin 10%.
Astfel, sunt necesare doua tipuri de masuratori la
sol, care sa complementeze datele obtinute de Euclid:
a) Date
imagistice obtinute la sol:
Cea mai mare parte a regiunilor extra-galactice va fi scanata atat din
spatiu, de Misiunea Euclid, cat si de pe pamant, de un numar de misiuni
observationale la sol, aflate deja in desfasurare sau planificate pentru
viitorul apropiat. Consortiul Euclid a explorat mai multe optiuni de obtinere
de date la sol ce sunt in conformitate
cu adancimea si intervalul de lungimi de unda cerute, si a elaborat o strategie
de colaborare cu o serie de misiuni observationale la terestre:
- The Dark Energy Survey (DES) este o misiune
demarata in 2013, ce foloseste telescopul de 4 m Blanco de la Cerro Tololo
Inter-American Observatory(CTIO). Acest telescop va observa o arie de 5,000
grade2 din cerul sudic, folosind fotometrie g, r, i si z si o adancimea suficienta pentru calcului
redshifturilor fotometrice, complementand datele ce vor fi obtinute de Misiunea
Euclid.
-
Panoramic Survey Telescope and Rapid Response System (Pan- STARRS): PS1, primul
dintre telescoapele planificate de misiune, scaneaza cerul, din zona Hawaii,
din mai 2010. Pan-STARRS mai are
planificate alte trei telescoape. PS2 este o “clona” a telescopului PS1,
planificata pentru viitorul apropiat, ce va dubla puterea experimentului. Pentru
a indeplini cerintele Misiunii Euclid, ar fi necesara o scanare de 7,500 grade2
a calotei galactice de nord (North Galactic cap), efectuata de PS1 si PS2 si optimizata
pentru Euclid, ceea ce ar implica 70% din timpul total de observartie, pe o
perioada de 5 ani.
Datele obtinute de DES si
PS2 ar acoperi 12,500 grade2 in cazul in care nu ar exista nici o
suprapunere, reprezentand 83% din aria ce va fi acoperita de scanarea de
suprafata(wide) realizata de Euclid.
Exista mai multe optiuni
posibile pentru restul de 2,500 grade2 care raman neacoperite de
aceste observatii: fie o crestere a arie de scanare a DES, in cazul in care
acesta isi va termina scanarea de baza cu success inainte de lansarea Misiunii
Euclid, fie folosirea survey-ului Kilo
Degree Survey (KiDS) realizat de telescopul VLT Survey Telescope (VST) al ESO,
fie folosirea survey-ului de 20,000 grade2 efectuat de Large Synoptic Survey Telescope (LSST) la
adancimi mult peste necesarul pentru Euclid.
b) Date
spectroscopice obtinute la sol:
Pentru a testa parametrii spatiului de redshifturi fotometrice si, in consecinta,
a defini intervalele (binuri) in care tomografia efectului de lentila este
efectuata, Misiunea Euclid are nevoie de un esantion de cel putin 100, 000 de
redshifturi fotometrice la o magnitudine limitata de VIS la 24,5.
In acest caz, nevoia de date obtinute la sol este oarecum limitata
deoarece in intervalul de redshift in care se inregistreaza cea mai mare parte
a semnalului specific efectului de lentila (0.7 < z < 2.0) o parte din
informatii pot fi furnizate de Euclid printr-o scanare spectroscopica slitless
de adancime.
Redshifturile ramase, inclusiv cele pentru galaxiile cartografiate de
Euclid la z < 0.7 si populatiile timpurii de stele in formare, sunt
acoperite de misiuni incheiate, aflate in desfasurare sau planificate. De
exemplu BOSS observa in mod specific populatii timpurii si mai putin luminoase,
la z ~ 0.7. Experimentele din cadrul ESO/VLT (VVDS, zCOSMOS, etc) au colectat
deja cateva mii de spectre pentru galaxiile mai putin luminoase.De asemenea,
Euclid mai are la dispozitie date spectroscopice de la numeroase misiuni de
observare terminate sau aflate in desfasurare: DEEP2 ce foloseste telescoapele
Keck si are deja spectrele de la peste 50,000 de galaxii, VIPERS ce se
desfasoara la VLT, ESO VLT UDSz, VIMOS Ultra-Deep Spectroscopic Survey (Ultra
VISTA), K20, GMASS, GDDS, ESO-GOODS-South, etc.
De
asemenea sunt planificate numeroase misiuni de observare in adancime cu
telescoapele foarte mari existente in prezent si cu noua generatie de
telescoape extrem de mari (Extremely Large Telescopes)
si telescoapele radio corelate: Australian SKA Pathfinder (ASKAP), JWST, etc.
6.2.4 Pregatirea
cataloagelor LSS
Unul dintre obiectivele acestui proiect este
constrangerea proprietatilor energiei intunecate (DE) cu efectul Sachs-Wolfe
integrat (ISW). Efectul ISW poate fi detectat doar prin corealatiile
structurilor la scala larga (LSS) cu radiatia cosmica de fond (CMB). Analiza
semnal-pe-zgomot (S/N) a demonstrate ca survey-ul ideal pentru detectarea
efectului ISW din studii de cross-corelare trebuie sa acopere cel putin
jumatate de cer, sa aiba o distributie mediana de redshift de aproximativ 0.9
si sa fie capabil sa detecteze mai mult de 10 galaxii pe arcminut patrat. Toate
aceste conditii vor fi indeplinite de Misiunea Euclid, optimizata pentru detectarea
efectului de lentila gravitationala, de tip slab. Observarea corelatiilor intre
LSS si CMB reprezinta si o confirmare a ipotezei standard conform careia
distributia la scala larga a galaxiilor astazi provine din inomogeneitati
primordiale amplificate de instabilitatea gravitationala. Acest lucru este
direct reflectat de efectul evolutiei potentialelor gravitationale asupra
anizotropiilor CMB.
In prezenta faza, am finalizat prima etapa a
acestei analize: am creat un set de date omogen (catalog) de trasori de materie
extragalactici, la diferite redshifturi, folosind cataloagele publice de
galaxii de la experimentele 6dF Galaxy Survey, Sloan Digital
Sky Survey DR7 si 2dF Galaxy Redshift Survey. Acest catalog este reprezentat in
proiectie Aitoff in Figura 18. Toate sursele non-extragalactice au fost
selectate si indepartate din catalog.
De asemenea, utilizam si cataloagele simulate in
conditiile experimetului Euclid: catalogul Euclid-MICE, ce contine informatii
fotometrice in benzile VIS+NIR pentru aproximativ 20 de milioane de galaxii, pe
o suprafata de 500 grade2 , in intervalul de redshift 0 < z <
1.4 si catalogul Durham construit prin popularea halourilor obtinute din
Simularea Milenium cu galaxii utilizand modelul semi-analitic GALFORM, ce contine
pozitiile si viteze, informatii fotometrice in domeniile optic si infrarosu
apropiat (in diverse benzi) si informatii (flux si latime echivalenta) ale
diferitelor linii de emisie (inclusiv H-alpha)
Din aceste cataloage, am obtinut harti reprezentand proiectii 2D ale
densitatii si potentialului gravitational; aceste harti sunt stocate in format
Healpix, pentru a putea obtine ulterior spectrul de putere al
cross-corelatiilor dintre spectrul de putere al galaxiilor si hartile de
temperature ale CMB.
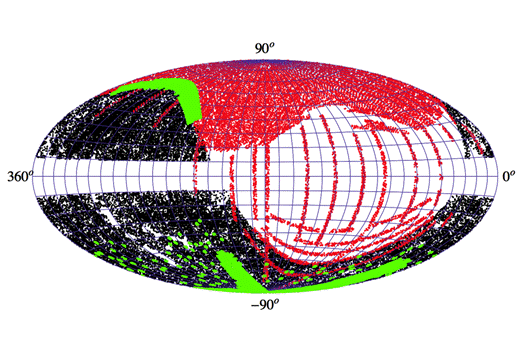
Figura 18. Proiectie Aitoff in coordonate galactice a trei
cataloage, 6dF Galaxy Survey (negru), Sloan Digital
Sky Survey DR7 (rosu) si 2dF Galaxy Redshift Survey (verde).
HEALPix (Hierarchical Equal Area
isoLatitude Pixelation), este un program de analiza de date,
simulari si vizualizare pe o sfera. Precum o sugereaza si numele, pixelizarea
produce o subdivizare a unei suprafete sferice, in care pixelii acopera aceeasi
arie egale.
HEALPix a aparut ca o necesitate, odata cu aparitia
seturilor de date cu rezolutie mare, la diferite frecvente, obtinute de
experimentele ce masoara anizotropiile radiatiei cosmice de fond (WMAP,
Planck). Astfel, programul contine o structura matematica care este capabila sa
realizeze o discretizare corespunzatoare a unei functii pe o sfera, la
rezolutie suficient de mare si o unelte software care faciliteaza analiza
statistica si astrofizica rapida si precisa a seturilor de date complete
all-sky. Are trei proprietati esentiale pentru analiza precisa a datelor
astrofizice: sfera este impartita in mod ierarhic in patrulatere cubilinii,
avand aspect de mozaic, ariile tuturor pixelilor la o rezolutie data sunt
identice iar pixelii sunt distribuiti pe linii de latitudine constanta.
Astfel, HEALPix este o unealta indispensabila in
analiza de fata, fiind capabil sa realizeze cu rapiditate si precizie crescuta:
-
Simulari rapide si analiza a
hartilor anizotropiilor de temperatura
si polarizare CMB pentru intreg cerul (full-sky) la rezolutii unghiulare
mai mari de un arcminut
-
Filtrarea hartilor astrofizice
cu ferestre circulare arbitrare
-
Transformari in armonice
sferice (scalare si spin-orientate)
-
Modificari si rotatii ale
coeficientilor armonicilor sferice ale hartilor arbitrare
-
Pixelizarea sferei pana la o
dimensiune minima a pixelilor de 0.4 mili-arcsecunde (aproximativ 3.5 x 1018
pixeli pe sfera)
-
Cautarea in harta a pixelilor
vecini si a extremelor unui camp aleatoriu
-
Filtrarea mediana a hartilor
ceresti
-
Facilitati de procesare a
mastilor
-
Etc.
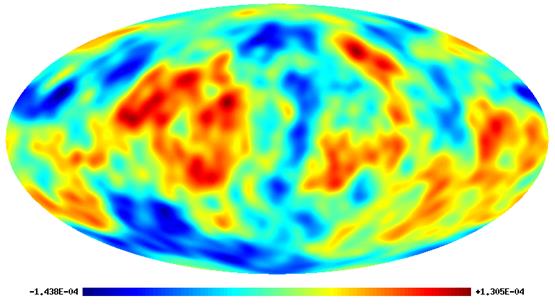
Figura 19. Harta
simulata a anizotropiilor de temperatura CMB, realizata cu subrutina synfast a HEALPix pentru un model
cosmologic dat si vizualizata cu ajutorul subrutinei map2gif
6.2.5 De asemenea, in aceasta etapa am demarat si
se afla in desfasurare activitatile de: implementare
a algoritmilor de compresie, decompresie si autotest, testarea a algoritmilor
cu date simulate si reale si simulari numerice de CMB
si LSS.
1.
Contextul
si contributia la programele ESA
Activitatile efectuate pe tot parcursul acestei
etape au sustinut participarea Institutulul de Stiinte Spatiale la activitatile
intreprinse de Consortiu pentru realizarea misiunii spatiale Euclid. Mai
precis, contributia ISS consta in implementarea unui algoritm de compresie a
datelor stiintifice obtinute de la cele doua instrumente ale Euclid.
2.
Concluzii
In aceasta etapa au fost facute progrese pentru
atingerea tuturor celor 4 obiective ale proiectului. Astfel, a fost proiectat
algoritmul de comprimare si a fost realizata o colectie de date de test,
necesare pentru realizarea obiectivului O1.Algoritmi
si teste de dezvoltare pentru compresia datelor primare obtinute de
instrumentele VIS si NISP; s-a incheiat etapa de definire a cerintelor si
strategiei pentru datele observationale la sol, necesara pentru realizarea
obiectivului O2. Calibrarea fotometrica
bazata pe analiza de imagini; au fost pregatite cataloagele LSS si
realizate hartile reprezentand proiectii 2D ale campului de densitate, pentru
realizarea obiectivului O3. Optimizarea
strategiei de masura din studiul efectului Sachs Wolfe Integrat
De asemenea au fost demarate activitatile de: implementarea
a algoritmilor de compresie, decompresie si autotest, testarea a algoritmilor
cu date simulate si reale si simulari numerice de CMB si LSS
In plus, membrii echipei CEM au contribuit si la realizarea celui de-al
4-lea obiectiv al proiectului, O4.Diseminare si outreach,
prin participarea lor la:
-
Intalnirea anuala a Consortiului Euclid
-
Evenimentiul anual Noaptea
Cercetatorilor
-
Interviuri acordate posturilor de
radio
-
Realizarea de reportaje,
comunicate de presa si articole de popularizare
La toate evenimentele descrise mai sus au fost evidentiate contributiile
aduse de ISS la Misiunea Euclid precum si importanta unei astfel de misiuni si
importanta participarii Romaniei la o misiuni spatiale ESA.
Tinand cont precizarile de mai sus, concluzionam ca
obiectivele prezentei etape a proiectului au fost realizate in conformitate cu
Planul de Realizare.
Bibliografie:
HEALPix: http://healpix.sourceforge.net/
Aladin: http://aladin.u-strasbg.fr/
K. Kovac et. al,
The Astrophysical Journal, 708:505–533, 2010
Planck Collaboration: P. A. R. Ade et al, 2013
[arXiv: 1303.5079]
Euclid Definition Study Report, ESA/SRE(2011)12
NISP Instrument Operation Concept Document,
EUCLID-IIO-NPS-PL-077 (internal)
VIS Instrument Operation Concept Document,
EUCLID-MSS-VIS-PL-00020 (internal)
Lossless data compression, Informational report,
CCSDS 120.0-G-2, 2006
A Rice-Based Lossless data Compression System for
Space Applications, Salvatore Coco, Valentino D’Arrigo, Domenico Giunta
GR712RC development board production sheet
GR712RC development board User Manual
Aeroflex Gaisler – GRMON Users Manual : http://www.gaisler.com/dor/grmon.pdf
http://www.gaisler.com/index.php/products/operating-systems/vxworks?task=view&id=241
http://www.gaisler.com/index.php/products?option=com_content&task=view&id=39
14/11/2013 Director
proiect
Dr.
Lucia A. Popa
ANEXA Indicatori de rezultat.
ANEXA RST
Indicatori de
monitorizare/rezultat
|
Nr. crt. |
Denumirea indicatorului |
|
|
1 |
sume
atrase prin participarea la programele ESA (EURO) |
|
|
2 |
nr. de
nişe CDI identificate |
|
|
3 |
nr. de
programe opţionale ESA la care se participă1 |
|
|
4 |
nr. de
misiuni spaţiale ESA la care participă entitățile implicate în
realizarea proiectului2 |
1 Euclid |
|
5 |
nr. de
experimente şi sarcini utile îmbarcabile la bordul misiunilor ESA |
2 VIS si
NISP |
|
6 |
nr. de centre
de profil nou înfiinţate |
|
|
7 |
nr. de
institute naţionale de CDI / entităţi de CDI / universităţi participante la
realizarea proiectului |
1 |
|
8 |
nr.
entităţi din industrie participante la realizarea proiectului |
|
|
9 |
nr. de
companii naţionale aflate în lanţul de furnizori pentru marii integratori de
produse spaţiale3 |
|
|
10 |
ponderea
participării diverselor entități în cadrul proiectului (industrie,
institute naţionale de CDI, entităţi de CDI, universităţi) (%) (se raporteaza
bugetul total alocat entitatii pe etapa la bugetul total al proiectului) |
|
|
11 |
nr. de
cursuri de instruire/perfecţionare organizate |
|
|
12 |
nr.
activități de diseminare organizate
(workshopuri/seminarii/conferințe etc.) |
7 |
|
13 |
nr.
cereri brevete depuse national/international |
|
|
14 |
nr.
brevete înregistrate national/international |
|
|
15 |
nr.
articole publicate sau acceptate spre publicare4 |
42 |
|
16 |
nr.
carți publicate sau acceptate spre publicare5 |
|
1) se vor
preciza denumirile programelor optionale ale ESA la care se participă
2) se vor
preciza denimirile misiunilor spațiale ESA la care se participă
3) se va
preciza denumirea integratorului(lor) de produse spațiale
4) se
anexeză lista articole
5) se
anexează lista cărți